ML_Linear_Regression
线性回归的概要
- 监督学习
- 拟合的Function为一次多项式函数,线性
- 梯度下降最小化代价函数
- 线性函数拟合: (只有一个变量的情况)
代价函数
- 代价函数的选择: 注:之所以多乘了一个1/2是为了在梯度下降求偏导时简化计算,后面的平方求导后正好多出来一个2倍
- 需要注意的是,代价函数的选择并不是随意的,因为后面的梯度下降求偏导最优化代价函数的时候,算法会在任何一个极小值点停下来,即梯度为0向量的点,在线性回归中,我们可以选择均方和作为代价函数,但是在逻辑回归中,同样的方法不再适用,因为逻辑回归的均方和非凸
梯度下降最小化代价函数
-
目标:需要最小化
-
直观地理解:如下图所示,横轴纵轴分别为\theta_0\theta_1,纵轴表示误差大小
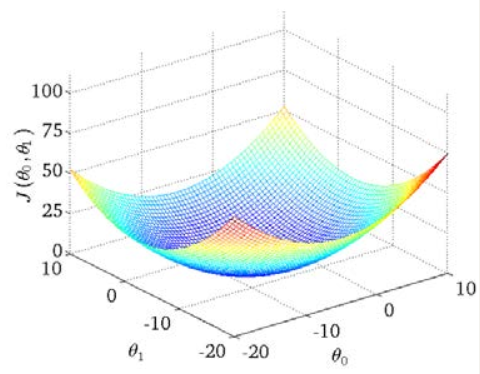
最小化代价函数的过程就是下坡的过程,当走到最底部,我们也就得到了局部最优化的拟合直线,由于代价函数的为凸函数,我们有唯一的极值点,局部最优即为全局最优。那么,我们怎么才能保证自己能以最快的速度下坡呢?用最直白的话来讲,就是走最陡的坡最快,下面我们将以严格的数学推导来解释这一过程。
-
数学推导:我们仍以 两个待估参数的情况来说明
-
首先,我们需要引出方向导数的概念,方向导数即函数在某一点沿着任何方向的变化率,有了方向导数的定义我们定义一个单位方向向量以描述各个方向 取一个小的增量,然后根据导数的定义表示出方向导数:
-
第二个等式到第三个等式由拉格朗日中值定理及函数的连续性给出,不赘述
-
第四个等式应该提前说明
-
最后我们可以看到,对于一个平滑的曲面,我们可以将方向导数写成两个向量内积的形式,不妨设,,那么方向向量为何时方向导数最大呢?答案是显然的,当方向向量与重合时,此时L的方向导数取得最大值。故此,我们将 定义为梯度
-
-
得到梯度向量之后,我们只需要沿着梯度方向向下走就可以走到谷底
求梯度:
更新参数,“下坡的过程”
如此迭代,直至找到最优点。
梯度下降中需要注意的问题
特征缩放
-
问题描述:在多维特征问题的时候,我们要保证这些特征具有相似的尺度,以保证梯度下降算法尽快的收敛
-
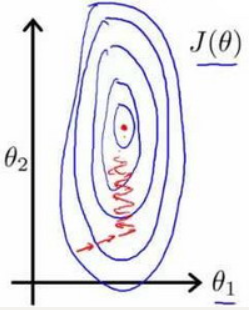
举例:以房价问题为例,假设我们使用两个特征,房屋的尺寸和房间的数量,尺寸的值为 0-2000平方英尺,而房间数量的值则是0-5,以两个参数分别为横纵坐标,绘制代价函数的等高线图能,看出图像会显得很扁,梯度下降算法需要非常多次的迭代才能收敛。参数的尺度相差过大,导致“抖动”,变化一点点对的影响都是巨大的。
-
解决方案:将特征进行标准化,其中 是平均值,是标准差。
- 当样本量足够大,我们可以近似所有的统计量都服从正态分布,所以我们可以简单地对参数进行标准化,经过标准化之后绝大部分数据被限制在【-1,1】之间
- 当然,不一定所有的变量都是服从正态分布,这需要我们根据具体的统计模型选择合适的特征缩放方法
学习率的设置
- 问题描述:梯度下降算法的每次迭代受到学习率的影响,如果学习率过小,则达到收敛所需的迭代次数会非常高;如果学习率过大,每次迭代可能不会减小代价函数,可能会越过局部最小值导致无法收敛
- 学习率我们可以看作每一次 “下坡”的步子有多大,步子大了,依然会产生左右横跳的“抖动”,步子小了,模型收敛速度又会太慢
- 自适应学习率算法:由于学习率的设置至关重要,因此也涌现了一些自适应的学习率算法旨在寻找最优学习率。(埋坑
正规方程(Normal Equation)
正规方程对于小规模的数据是更好的方法,但是当特征数量n太大的时候运算的代价也会更大,矩阵逆的计算时间复杂度为
的推导过程:
其中:
将向量表达形式转为矩阵表达形式,则有 ,其中为行列的矩阵(为样本个数,为特征个数),为行1列的矩阵,为行1列的矩阵,对进行如下变换
接下来对偏导,需要用到以下几个矩阵的求导法则:
所以有:
令,
则有
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 2542608082@qq.com